Evolution Strategies Lora
layout: post(v3)
title: “Evolution Strategies with LoRA”
date: 2025-11-11
categories: [research, LLMs, evolution-strategies]
Overview
This post presents early experimental results from ongoing work on applying Evolution Strategies (ES) to optimize LoRA adapters instead of full model parameters. While LoRA fine tuning is highly parameter efficient, these initial experiments explore whether its performance can match that of full parameter fine tuning.
This work builds on the framework introduced in Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning (arXiv:2509.24372v1), which proposed the conciseness task as a lightweight benchmark for evaluating ES based fine tuning methods. The experiment here follows that same setup, training on two prompts and evaluating on eight distinct test prompts to assess generalization and reward stability.
This is the first evaluation of LoRA under ES. The goal is not to draw definitive conclusions, but rather to better understand how low rank parameterization interacts with gradient free optimization and to identify directions for improvement in future iterations.
Background
Evolution Strategies (ES) is a gradient free optimization method that updates model parameters via random perturbations and reward weighted averaging:
where:
- — Gaussian noise applied to parameters
- , — normalized reward
- — learning rate controlling step size
In LoRA fine tuning, we reparametrize weight updates as:
with and ,
where , reducing the number of trainable parameters. This low rank decomposition lets us fine tune large models efficiently by updating only a small subset of parameters.
Experimental Setup
Dataset and Evaluation
The experiment focused on a single task: conciseness. Qwen-2.5-7B-Instruct was trained on two short prompts and evaluated on eight generalization prompts.
Training Prompts
| Prompt | Target |
|---|---|
| Solve: 3 + 5 = | 8 |
| If all birds can fly and penguins are birds, can penguins fly? | No |
Test Prompts
| Prompt | Target |
|---|---|
| What is the capital of France? | Paris |
| Calculate: 12×7 = | 84 |
| Is the statement “All cats are mammals” true or false? | True |
| What comes next in the sequence: 2, 4, 6, 8, ? | 10 |
| Translate “Hello” to Spanish: | Hola |
| What is 15% of 200? | 30 |
| Name one primary color: | Red |
| How many days are in a week? | 7 |
Reward Function
The reward measures how concise and length aligned the model’s answer is with the target output:
Reward = −|len(generated_text) − len(target_text)|
That is, the closer the generated response length is to the target’s length, the higher (less negative) the reward.
This simple heuristic encourages concise, targeted answers rather than verbose outputs.
Model: Qwen-2.5B-7B-Instruct (added 11/11/25)
** The initial results posted here contained a methodological error in the LoRA implementation. As @Green0-0 identified (see GitHub discussion), simultaneously perturbing both A and B matrices in LoRA does not yield effective results. The matrices must be perturbed alternately. I’ve preserved the original results below in the appendix with their timestamps to demonstrate the iterative nature of research and the value of community feedback in identifying and correcting errors.
Evolution Strategies (ES) Hyperparameters - LoRA Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.0075 | Standard deviation of Gaussian noise |
| ALPHA | 0.005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
LoRA Configuration
| Setting | Value | Description |
|---|---|---|
| LORA_R | 256 | Rank (low-dimensional bottleneck size) |
| LORA_ALPHA | 256 | Scaling factor for LoRA updates |
| LORA_DROPOUT | 0.1 | Dropout applied to LoRA layers |
| LORA_TARGET_MODULES | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj | Targeted transformer submodules for LoRA adaptation |
Evolution Strategies (ES) Hyperparameters - Full Fine-tuning Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.001 | Standard deviation of Gaussian noise |
| ALPHA | 0.0005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
This setup establishes a compact testbed for studying how Evolution Strategies interact with LoRA’s low rank parameterization, offering a clean, reproducible baseline for further experiments.
Results
Best iteration taken for Full Parameter and Lora shown below in images. Model was evaluated every 10 iterations.
Full: Iteration 180
Lora: Iteration 990
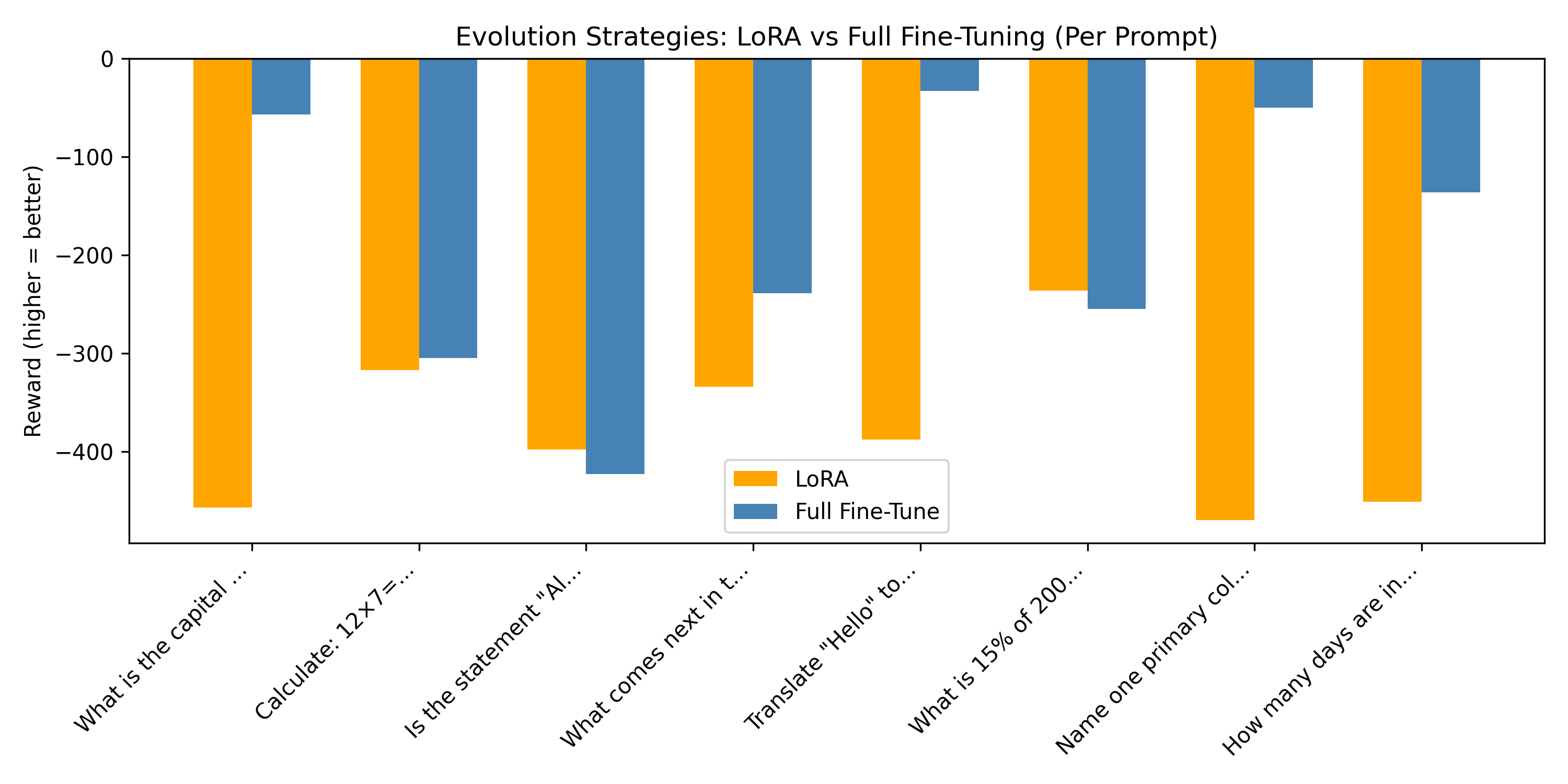
1. Per Prompt Reward Comparison

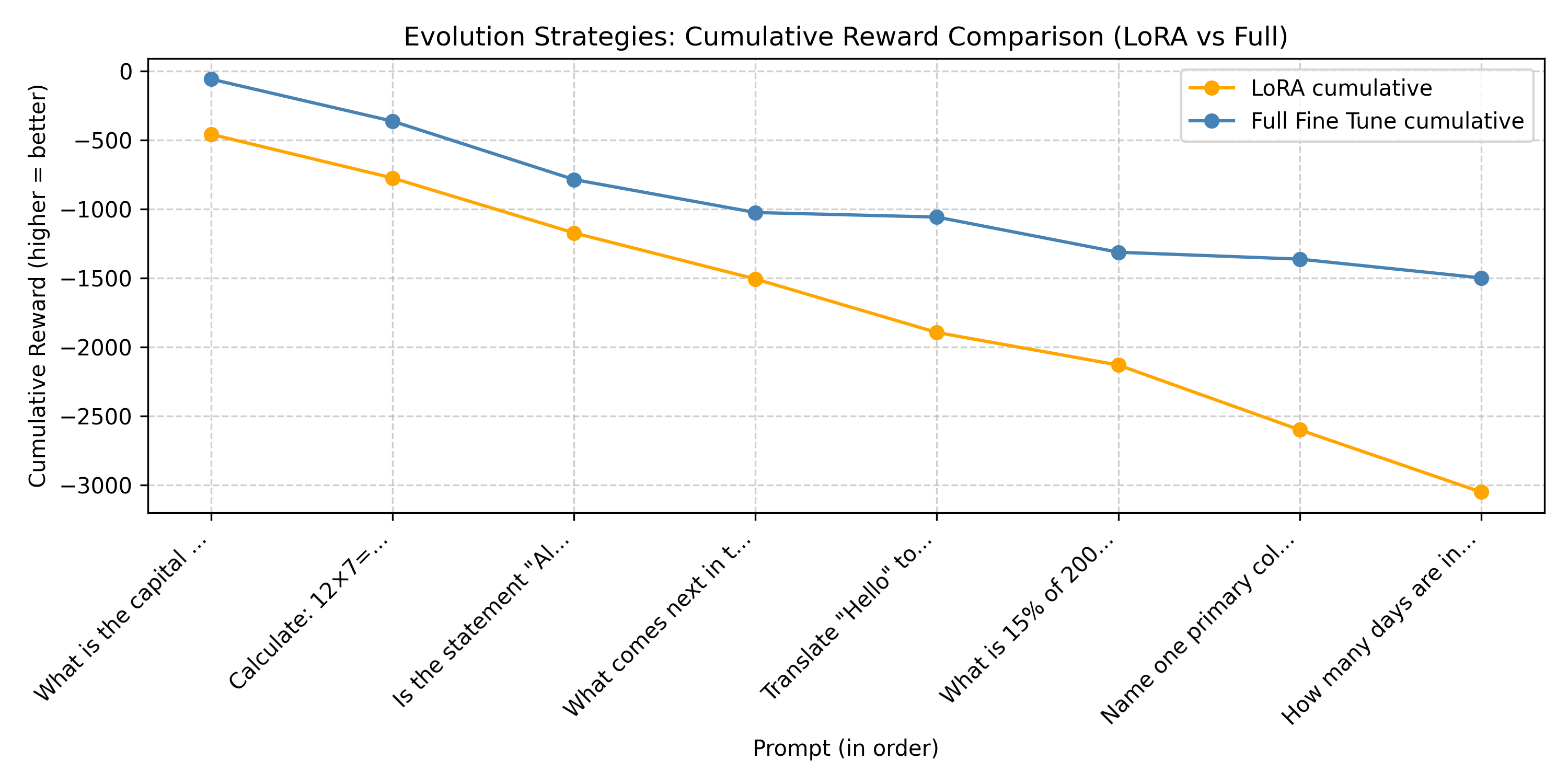
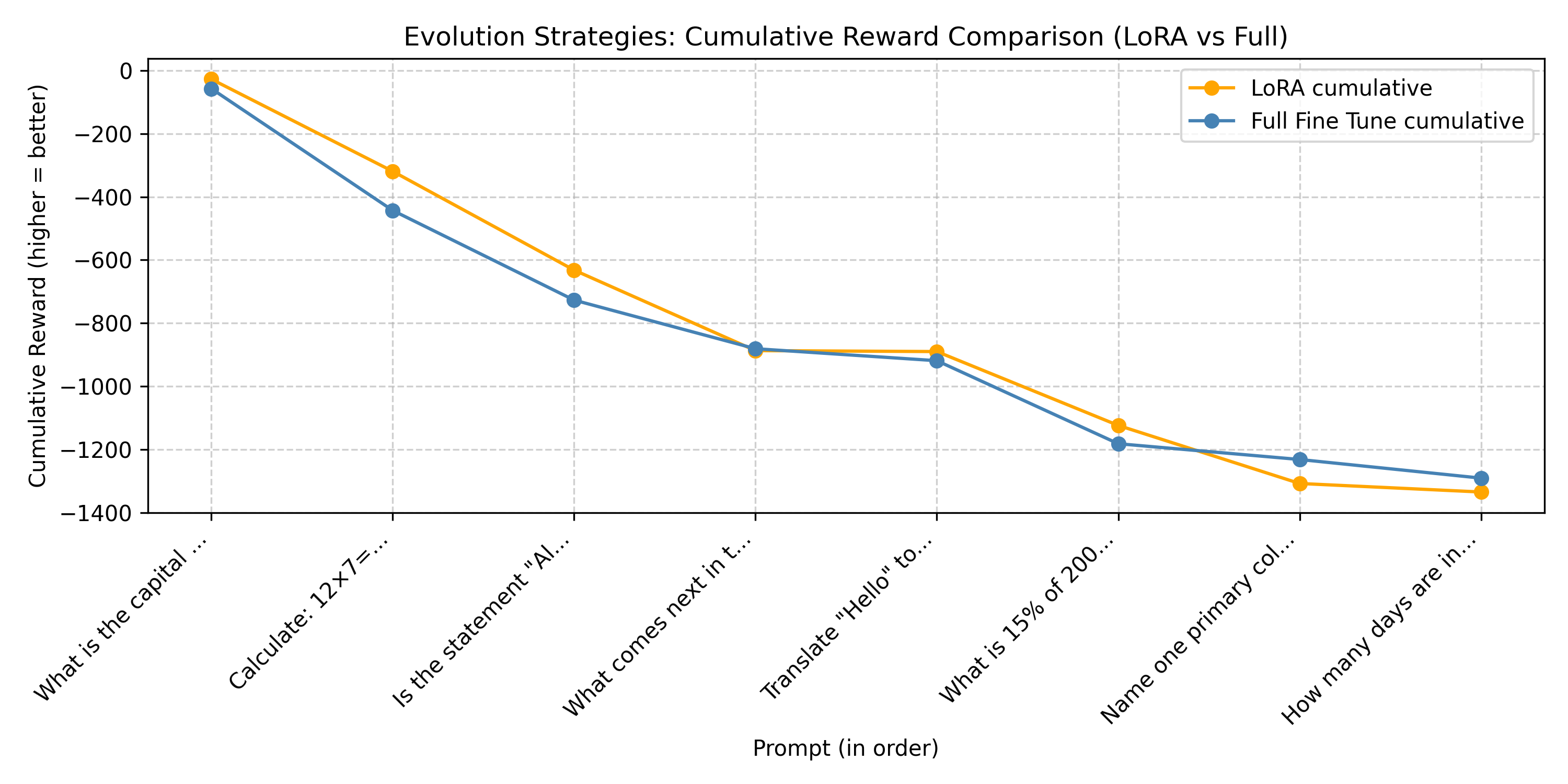
2. Cumulative Reward Over Prompts
Cumulative reward reflects total progress as more prompts are evaluated.

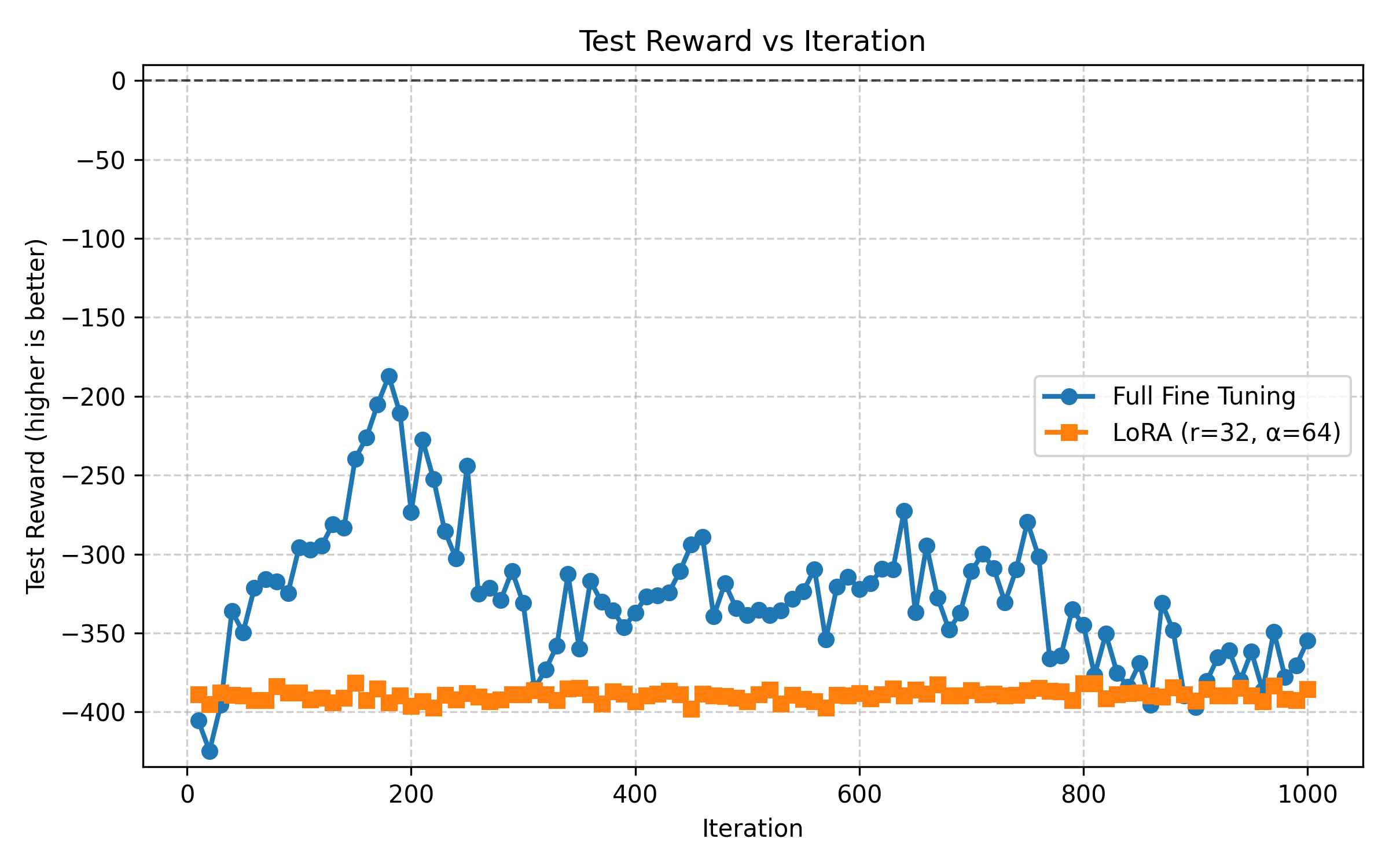
3. Reward Progression Over Iterations
The figure below visualizes test reward progression across 1000 Evolution Strategies (ES) iterations for both LoRA and full fine tuning. The horizontal dashed line at 0 represents the ideal reward (perfect target-length match).

For full parameter fine tuning, Figure 3 shows overfitting: while training reward improved to approximately -80, test reward degraded from -190 to -360, indicating the model memorized the training examples rather than learning generalizable patterns.
Note that this was a small, toy task with only two training examples.
Discussion
The results presented above represent a preliminary exploration comparing LoRA and full parameter fine tuning using Evolution Strategies on a constrained text generation task. While limited to a single hyperparameter configuration, several key observations emerge from the data.
Performance Comparison: LoRA achieved superior performance compared to full-parameter tuning on this task, reaching its best results at iteration 990 versus iteration 180 for the full parameter approach. The bar plot (Figure 1) reveals that LoRA maintains more consistent per prompt rewards, while the cumulative reward plot (Figure 2) shows LoRA’s advantage compounds across the evaluation set. Most notably, the iteration progression plot (Figure 3) demonstrates that LoRA converges more smoothly toward the target reward (dashed line at 0), suggesting better optimization stability with ES.
Limitations and Scope: These findings should be interpreted cautiously. The experiment was conducted on a relatively simple length matching task with a single hyperparameter configuration. The task’s simplicity may not reflect the challenges present in more complex fine tuning scenarios where full parameter methods might show different relative performance. Additionally, the computational efficiency advantages of LoRA (lower memory footprint, faster iteration times) weren’t quantified here but represent important practical considerations.
Broader Context: Despite these limitations, the results align with the hypothesis that low rank adaptation may provide a more navigable optimization landscape for Evolution Strategies, potentially due to the reduced parameter space constraining the search. This could explain both the improved final performance and the smoother convergence trajectory observed in Figure 3.
Community Collaboration: These experiments build upon ongoing community efforts to understand ES fine tuning dynamics. Notably, @Green0-0 conducted complementary experiments on the Countdown task from the original ES fine tuning paper, exploring a broader hyperparameter sweep (see GitHub discussion).
Future Directions: To establish more robust conclusions, future work should include: (1) systematic hyperparameter sweeps for LoRA, (2) evaluation on diverse tasks of varying complexity, (3) computational cost analysis, and (4) investigation of scaling behavior with model size. Nevertheless, these initial results suggest that LoRA based ES fine tuning warrants further investigation as a potentially promising approach for parameter efficient LLM adaptation.
References
- Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning
arXiv:2509.24372v1 - LoRA: Low-Rank Adaptation of Large Language Models
arXiv:2106.09685
Appendix
Model: Qwen-2.5B-7B-Instruct (added 11/3/25)
Experiment where A and B (LoRA) were both perturbed in each ES generation step. This approach was later identified as methodologically flawed, as effective LoRA fine tuning requires alternating perturbations of the A and B matrices rather than simultaneous perturbations.
Evolution Strategies (ES) Hyperparameters - LoRA Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.0075 | Standard deviation of Gaussian noise |
| ALPHA | 0.005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
LoRA Configuration
| Setting | Value | Description |
|---|---|---|
| LORA_R | 256 | Rank (low-dimensional bottleneck size) |
| LORA_ALPHA | 256 | Scaling factor for LoRA updates |
| LORA_DROPOUT | 0.1 | Dropout applied to LoRA layers |
| LORA_TARGET_MODULES | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj | Targeted transformer submodules for LoRA adaptation |
Evolution Strategies (ES) Hyperparameters - Full Fine-tuning Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.001 | Standard deviation of Gaussian noise |
| ALPHA | 0.0005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
This setup establishes a compact testbed for studying how Evolution Strategies interact with LoRA’s low rank parameterization, offering a clean, reproducible baseline for further experiments.
Results
Best iteration taken for Full Parameter and Lora shown below in images. Model was evaluated every 10 iterations.
Full: Iteration 180
Lora: Iteration 150
1. Per Prompt Reward Comparison
2. Cumulative Reward Over Prompts
Cumulative reward reflects total progress as more prompts are evaluated.
3. Reward Progression Over Iterations
The figure below visualizes test reward progression across 1000 Evolution Strategies (ES) iterations for both LoRA and full fine tuning. The horizontal dashed line at 0 represents the ideal reward (perfect target-length match).
Model: Qwen-2.5-7B (added 10/27/25)
Experiment where A and B (LoRA) were both perturbed in each ES generation step. This approach was later identified as methodologically flawed, as effective LoRA fine tuning requires alternating perturbations of the A and B matrices rather than simultaneous perturbations.
Evolution Strategies (ES) Hyperparameters - LoRA Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.0075 | Standard deviation of Gaussian noise |
| ALPHA | 0.005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
LoRA Configuration
| Setting | Value | Description |
|---|---|---|
| LORA_R | 256 | Rank (low-dimensional bottleneck size) |
| LORA_ALPHA | 256 | Scaling factor for LoRA updates |
| LORA_DROPOUT | 0.1 | Dropout applied to LoRA layers |
| LORA_TARGET_MODULES | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj | Targeted transformer submodules for LoRA adaptation |
Evolution Strategies (ES) Hyperparameters - Full Fine-tuning Configuration
| Parameter | Value | Description |
|---|---|---|
| NUM_ITERATIONS | 1000 | Total ES optimization steps |
| POPULATION_SIZE | 30 | Number of perturbed samples per generation |
| SIGMA | 0.001 | Standard deviation of Gaussian noise |
| ALPHA | 0.0005 | Learning rate / step size |
| MAX_NEW_TOKENS | 100 | Maximum tokens generated per sample |
| INITIAL_SEED | 33 | Random seed for reproducibility |
This setup establishes a compact testbed for studying how Evolution Strategies interact with LoRA’s low rank parameterization, offering a clean, reproducible baseline for further experiments.
Results
When applying Evolution Strategies (ES) directly to the LoRA parameters, performance was very similar to full fine tuning across the eight test prompts, with only a small difference in mean reward.
| Method | Mean Reward | Standard Error |
|---|---|---|
| Full Fine-Tuning (ES) | −161.38 | 47.22 |
| LoRA (r=32, α=64, ES) | −166.88 | 45.43 |
The total cumulative rewards were −1291 for full fine-tuning and −1335 for LoRA, indicating that both approaches achieve comparable performance under ES optimization.
These early findings suggest that LoRA’s reduced search space does not substantially degrade performance in this simple task, though it may still limit how effectively ES explores high reward directions as task complexity grows.
1. Per Prompt Reward Comparison
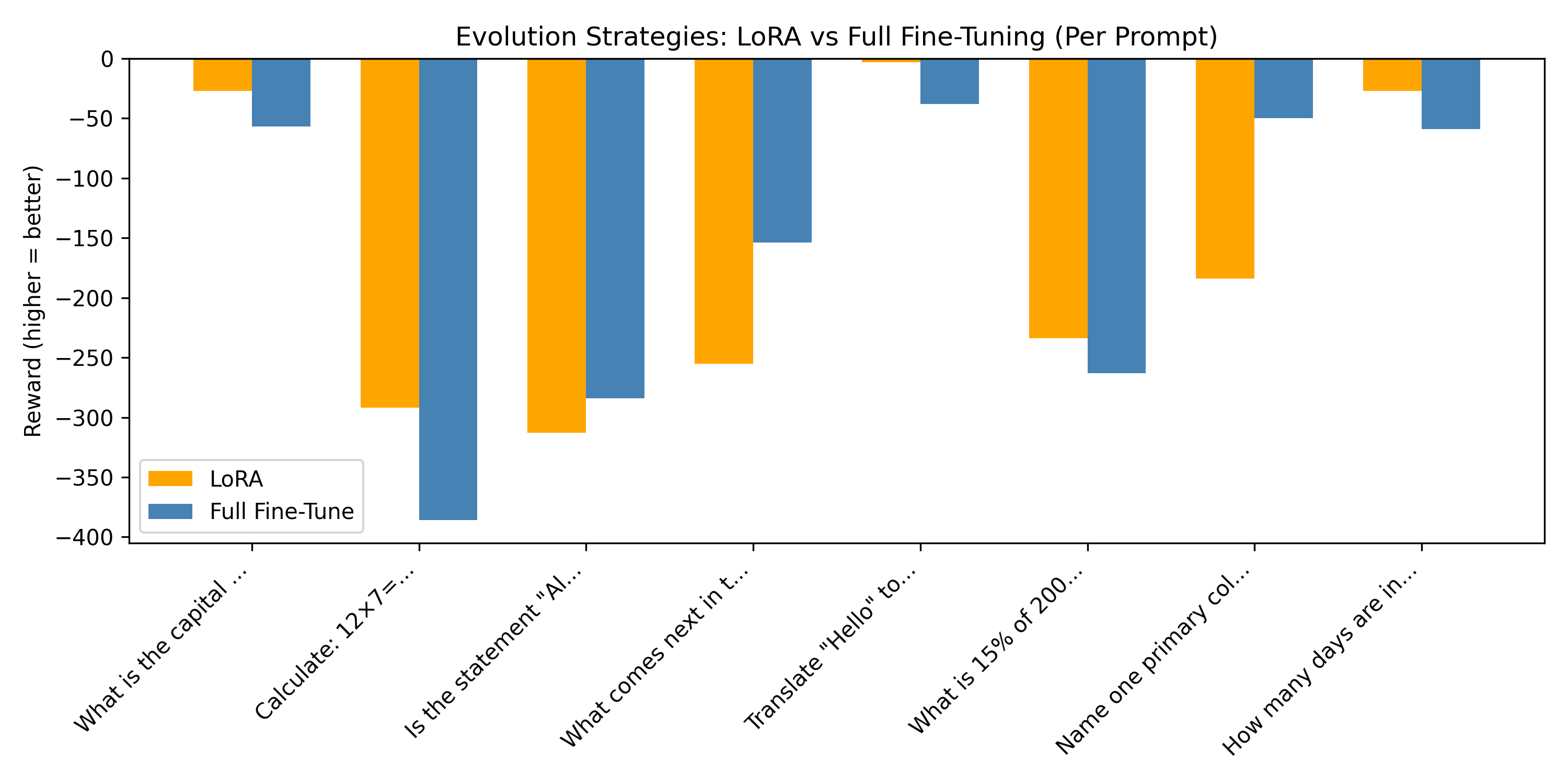
2. Cumulative Reward Over Prompts
Cumulative reward reflects total progress as more prompts are evaluated.
3. Reward Progression Over Iterations
The figure below visualizes test reward progression across 1000 Evolution Strategies (ES) iterations for both LoRA and full fine tuning. The horizontal dashed line at 0 represents the ideal reward (perfect target-length match).

Full fine tuning reaches −150 by iteration 500, while LoRA stays near −167, showing early convergence and limited improvement after. The results shown in a table earlier this section are the results after 1000 iterations.